
IEEE Extreme Programming Challenge 2008 (13)
Shortly after attempting IEEE Challenge 2008 (04), I decided to have a go at challenge number 13 - The Hard Life of a Mole. It turned out to be quite a challenge. So much so that I actually had a number of attempts using different methods before finally hitting on a solution that worked. Skip to the bottom of the page if you just want to see the source code, otherwise, read on.
From the challenge text:
Moles live underground and burrow holes. When travelling underground from point A to point B, any clever mole takes advantage of existing tunnels and minimizes the amount of digging through the soil. Of course, any rock must be circumvented because it is impossible to dig through a rock. Furthermore, any spot tainted with castor oil repellent should also be avoided because moles hate castor oil so badly that they are willing to dig longer tunnels to circumvent it. Unfortunately, sometimes there is no clear path available and the mole has no other option than, at some point, dig through the castor oil - Yuck! Disgusting!
Please, write a program that, given a map of the underground, computes the minimum amount of digging necessary to travel from A to B, circumventing the contaminated cells as most as possible.
Here is how the input data looks in a text editor:
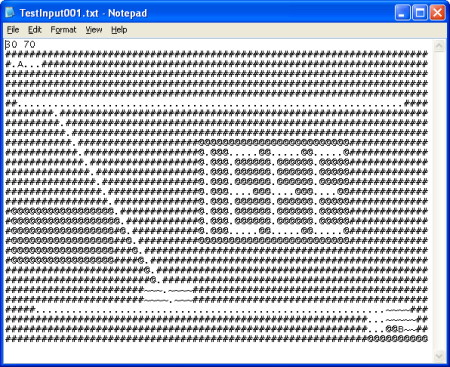
For my first attempt at solving this puzzle I tried using a depth first search starting from A and choosing a direction to head in until the path could either go no further, or point B was reached. Each possible move has an associated cost. Tunnels cost zero. Digging earth costs one and digging oil costs the sum of all the squares on the board to express the mole’s willingness to dig every other square, rather than dig a single square of oil.
The search would pass the cumulative cost of each move back up the tree to determine which moves lead to the cheapest path from A to B. I would use the cheapest cost so far as a way to prune the search from going too deep.
This solution worked perfectly … as long as you didn’t mind waiting a couple of weeks for it to finish. So, back to the drawing board.
For a second attempt I aimed to use the same idea as in the first attempt, but making use of the fact that the sample board could be partitioned into blocks of squares of the same type. It wouldn’t be necessary to search every route through a particular block as we can calculate the distance of the shortest path from edge to edge. Apparently this distance is known as the Taxicab Metric after the means of calculating distances driven by a taxi through a block based city like Manhattan.
This is how the sample input breaks down into blocks:
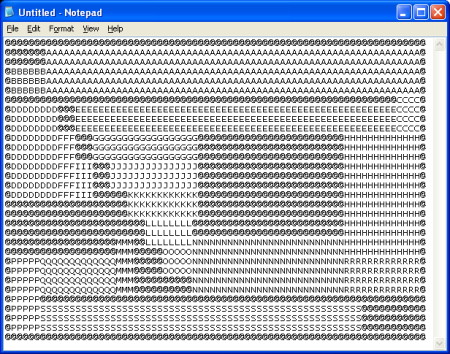
Unfortunately not only did this attempt also suffer from performance issues, but it also didn’t work properly. It is possible to create a board where it is necessary to enter a block and leave it on the same side in order to reach the solution. This meant I couldn’t use the block shortcut.
At this point I shelved the problem and went away to do some reading on the subject of Pathfinding Algorithms, in particular the well known A* algorithm which looked like it might help. This page contains some excellent information on the subject.
After much reading and trying out of ideas (on paper this time) I came across a little snippet on this page that seemed to confirm a suspicion I’d had that what I wanted to do would be tricky:
I strongly advise that you do not make road movement free (zero-cost). This confuses pathfinding algorithms such as A*, because it introduces the possibility that the shortest path from one point to another is along a winding road that seems to lead nowhere. The algorithm has to search a very wide area to make sure that no such roads exist.
Of course our puzzle has this problem because movement along tunnels is zero cost. Besides which, A* is generally used to produce an approximate best path, whereas for the challenge I wanted the best path.
I came upon the idea for my third and final working attempt in stages. First I worked out a very simple algorithm to decide whether or not a given map was solve-able. This involved running a Flood Fill algorithm using the start position as a seed. When the fill is finished, I know the puzzle is solve-able if the flood has filled the end square on the grid.
I used a stack based implementation for this as my initial attempt at a recursive solution produced very elegant looking code, which unfortunately didn’t work as the repeated function call overhead eventually caused a stack overflow. The stack based version successfully completes in milliseconds.
Following some sage advice handed to me many years ago by my father I decided that if I was going to solve this problem properly I needed to be able to visualize what was going on. My father’s advice actually concerned woodworking and the value of taking the time to ensure that you are in a comfortable position with the job securely fastened for you to work on it, but it seemed relevant here.
So, I concocted a little Windows application to display the puzzle grid and intermediate solution steps on screen. I made use of some light weight library code at ReliSoft from their Win32 tutorial and Frequency Analyzer sample program. I find this preferable to using the Microsoft MFC classes as a lot less code gets built into the application.
Also, now that I have upgraded my compiler to the free Visual C++ 2008 Express Edition I no longer have access to the MFC. Not that I’m complaining - I think the VC++ compiler is an excellent product, and not just because many years ago I helped to write a tiny part of one of its predecessors.
This is the application displaying the sample input data:
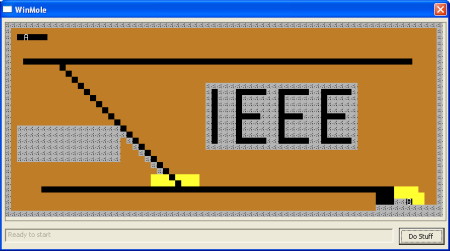
This is what the sample map looks like after every visitable square has been visited by the flood fill algorithm. You can see how the spaces surrounded by rock will never be reached by the mole.

As an experiment I altered the flood fill code to record the cost of moving back to the start point using the same values for cost as in the original search-based solution. This was very simple to do as the cost from any given square to the start is the cost from the square before to the start, added to the cost to get from that square to the square in question. It would be simple if I explained it properly.
This first pass produced the following result. Looks good, but definitely isn’t the best possible route.
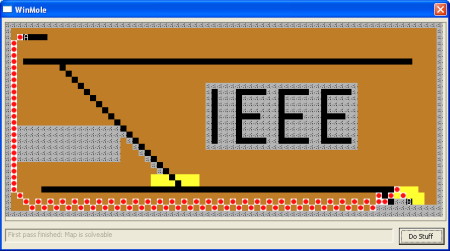
The reason this isn’t the best possible route is because the costs of routes from squares back to the start was built up step by step. We therefore didn’t take into account the phenomenon mentioned above where a long winding tunnel could take you to the goal for free, vs having to dig a much shorter direct route through earth.
However, we now have a map of the cost to get from any visitable square back to the start. It is now reasonably straightforward to search through that map to find squares where travelling via a neighbour would be cheaper. We update those squares as we find them. Those updates may in turn trigger other updates but that issue is easily taken care of by simply repeating the scan until no more updates are found.
At this point each square will contain the cost of the cheapest route back to the start and a grid reference for the next square on that route. We can then start at the end and work backwards counting up squares to reach the solution.
Here is the map after a first scan for a cheaper solution:
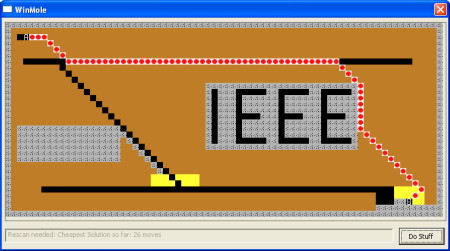
We’re still not done, though. After one more scan we reach the final solution, although that isn’t confirmed until another 29 scans during which paths not on the cheapest path get altered. Of course we don’t know which paths are which, so we have to do all of the necessary scans. This is the final answer, produced in well under a second:
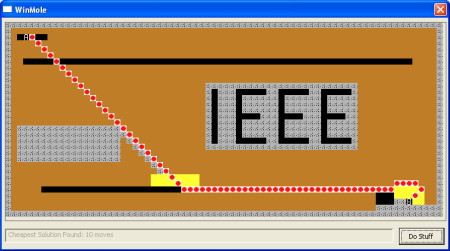
Full source code for the command line competition version of the program: Mole.h Mole.cpp
Post Script
I’m delighted with the improvement in this program that came from using a sensible algorithm. I finished up with something much smaller and far more elegant than my initial attempts at a solution.
There are still plenty of ways performance could be improved. Most notably by replacing the use of Boost::multi_array with a more efficient solution. I did some separate tests which suggest that multi_arrays are an order of magnitude slower than comparable “vector of vector” implementations, which in turn perform slower than a simple two dimensional C array. However, this is way beyond the scope of the original competition and so I have left it for now.
Special thanks to the authors of the Relisoft Library (not a part of the competition version of the code) and the excellent Boost C++ Library



